2022/09/06
论文阅读:
- Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- PointCLIP: Point Cloud Understanding by CLIP
- CLIPstyler: Image Style Transfer with a Single Text Condition
- StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
- A Style-Based Generator Architecture for Generative Adversarial Networks (StyleGAN)
实验:
- 利用 CLIP 做简单的图片检索
Learning Transferable Visual Models From Natural Language Supervision
CLIP 模型的本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当。
CLIP 模型使用的方法:对比学习,预测 n*n 对图像与文本数据,将图片分类任务转换成图文匹配任务。这个过程实际上就是引入了 NLP 给出的监督信号。
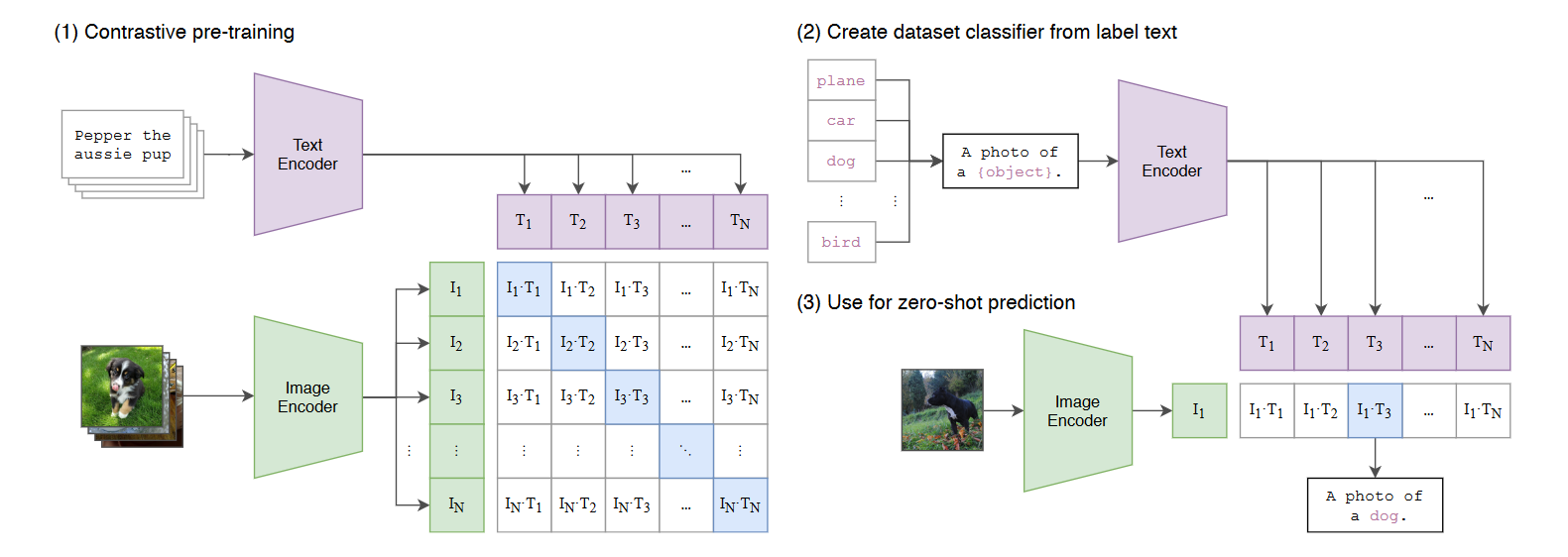
图中左侧,得到文本特征与图片的特征后可以看到,对角线上的元素都是图文匹配的,共有 N 个正样本,其余的元素都是负样本,共有 N*N-N 个。其中,文本数据使用Transformer,图片数据用了两种模型,ResNet 和 Vision Transformer (ViT)。
CLIP 模型训练所用的数据集较为庞大,包含从互联网上各种公开资源收集的4亿对图像、文本,CLIP是从头开始训练的,没有使用预训练的初始参数。
PointCLIP: Point Cloud Understanding by CLIP
这是第一篇把 CLIP 用在点云上的工作,重点解决的是如何利用 CLIP 去理解点云数据。
对于点云这种 3D 数据的形式,为了抽取点云的特征,采用了投影的方式,把三维的点朝 M 个方向投影,得到 M 张不同方向的 2D 点云深度图。这种图文章中提到是符合透视画法的特征:近大远小,即更加符合照片的特征。每个方向上得到的图片都是没有色彩信息的,作者这里出于运算时间与资源消耗的考虑,直接将图层复制成三个完全一致的通道传入编码器。
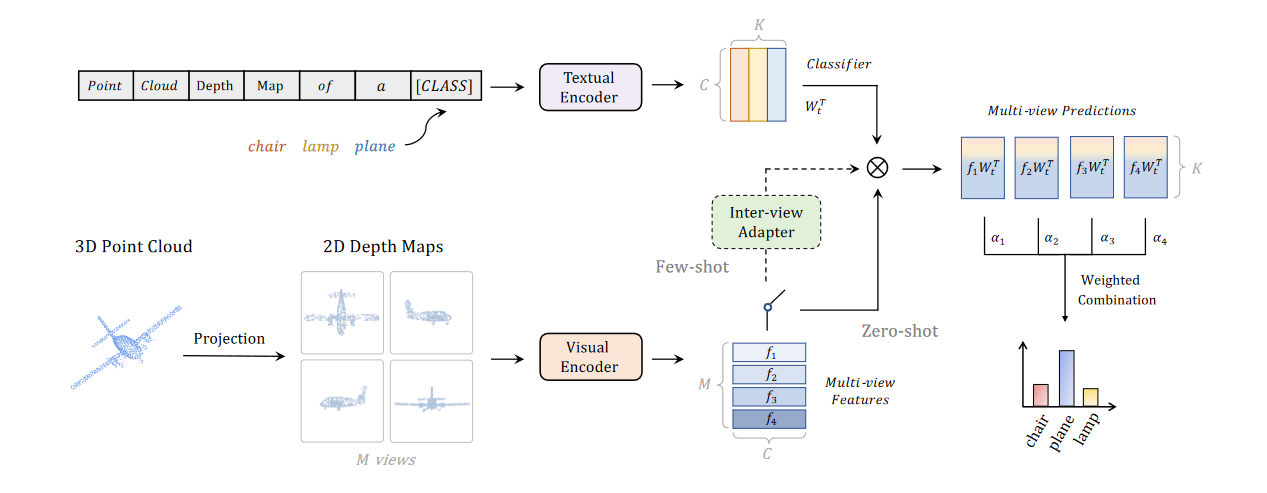
关于这种方法(PointCLIP)的效果,文章先是做了 zero-shot 分类的实验,在 ModelNet40 数据集上准确率是 20.18%,在 ScanObjectNN 数据 集上的准确率只有 15.38%,虽然这说明这样的方法是有一定效果的,但依然没法与现有的训练好的直接学习 3D 数据的网络相比较。
然后作者提到 ModelNet40 需要六个方向的视图以不同的权重贡献作出最后的分类结果,在 ScanObjectNN 这样带有噪点(地板和天花板)的数据中,顶视图与底视图几乎提供不了任何有效信息(所以效果不好)。对于视图的数目,作者尝试了 1,4,6,8,10,12,在 zero-shot 任务里 6 个视角效果最佳(后面16-shot实验里10视角最佳);关于不同视图的贡献,实验里右视图和左视图最多。
当然,和 CLIP 有关的任务里,肯定也要涉及到 Prompt Design 的问题,作者这里用了以下的 Prompt:
1 | a photo of a [CLASS]. |
再就是图像编码器的选择,作者使用RN.*16的效果在zero-shot中表现最佳,使用RN101在16-shot中表现最佳。
zero-shot 的方式相对于有监督的方法效果较差,于是作者又加了一个小网络 few-shot finetune 一下。将 M 个特征图拉成一维然后经过两个全连接得到一个全局特征,然后用这个全局特征在通过以下公式得到 M 个特征,与原先的特征残差连接得到新的 M 个特征。
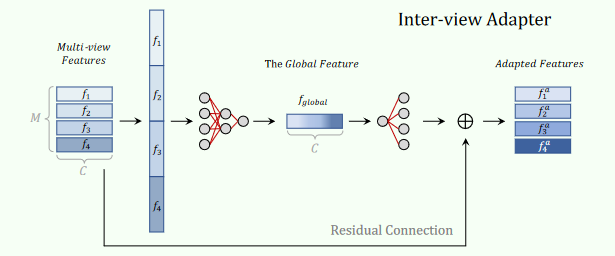
这样一来,效果就有了大幅度的提升,在 ModelNet40上的结果从20.18%提升到了87.20%,据说是只用了1/10的数据就达到了这样的效果。
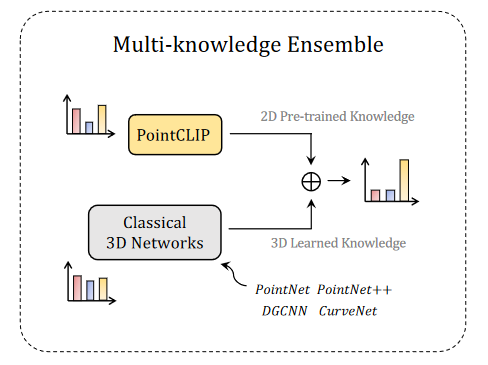
最后,作者考虑是否可以通过模型融合的方式得到更好的效果,简单地说就是将不同模型预测的各类别分数相加得到最终分数。通过实验,用 PointCLIP 和其他有监督方法得到的模型融合,结果有所提升。PointCLIP 和 CurveNet 融合的结果达到了 sota。两个效果最好的有监督模型融合得到的效果与之相比反而达不到最高。
CLIPstyler: Image Style Transfer with a Single Text Condition
现有的神经风格迁移需要提供参考图像才能将纹理信息转移给目标图像,但是在很多情况下用户手头是没有参考图像的。这篇文章提出了 CLIPstyler,旨在使用简单的对风格的文字描述来进行风格迁移。
问题的两个难点在于:1)如何释放来自 CLIP 模型的语义化的“材质”信息,将其应用到目标图片上;2)如何规范化训练,使得输出的图像不会受质量上的影响。
作者这里设计了一个 StyleNet 用来捕捉内容图像的分层视觉特征,同时在深度特征空间中对图像进行风格化处理,以获得真实的纹理表示。
关于损失函数,作者这里阐述了几个他们用到的概念:
1) CLIP loss
最简单的基于CLIP的最小化全局损失函数如下:
$D_{CLIP}$ 指在 CLIP 空间的余弦距离。但是如果用这样的损失函数,图像的质量会受损,而且图像优化过程的稳定性无法保证,于是他们参考了 StyleGAN-NADA 提出的一种定向的 CLIP loss 函数,将图像-文本对的输入和输出在CLIP空间对齐,从而解决了上面的问题,这个损失函数如下:
其中 $E_T, E_I$ 指的就是 CLIP 的文本和图像编码器,$t_{sty},t_{src}$ 则是风格描述文本和原图像文本(默认设置为:Photo)
- PatchCLIP loss
上文的 $L_{dir}$ 在调整预训练的生成式模型效果较好,但是和作者的目标不完全一样,单纯使用这个损失函数也会造成输出质量的降低。为了解决这个问题,作者提出了一种新的专为纹理迁移设计的损失函数 PatchCLIP loss。他们将通过 StyleNet 得到的图像随机地分成一些块(块的尺寸固定),然后对不同的块做不同的数据增强,这里的增强统一使用了透视变换

透视变换的好处是,所有的分块在不同的点观察时都能够具有相同(或类似)的语义,CLIP 模型的语义信息也就可以被重建为更类似于 3D 的结构。
- Threshold rejection
由于分块的随机性,以上的方法很可能导致在某些已经具有较为符合目标风格的分块上进行过度的风格化(因为这样的分块更加容易被优化),针对这个情况,作者加入正则化,设定了一个阈值,当分块得分低于这一阈值时忽略这一分块的梯度优化过程。这样就得到了整个$L_{patch}$的定义:
- Total loss
最终总体的损失函数还加入了 content loss $L_c$ 和 total varation regularization loss $L_{tv}$:
CLIPstyler 有可供尝试的 demo,网址:https://replicate.com/paper11667/clipstyler
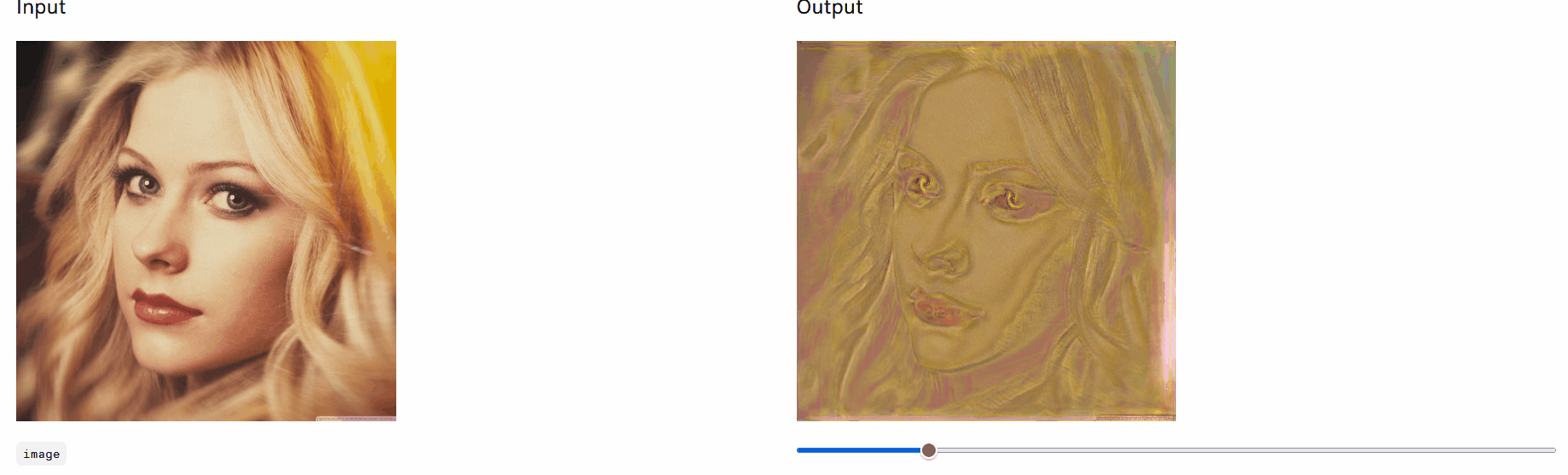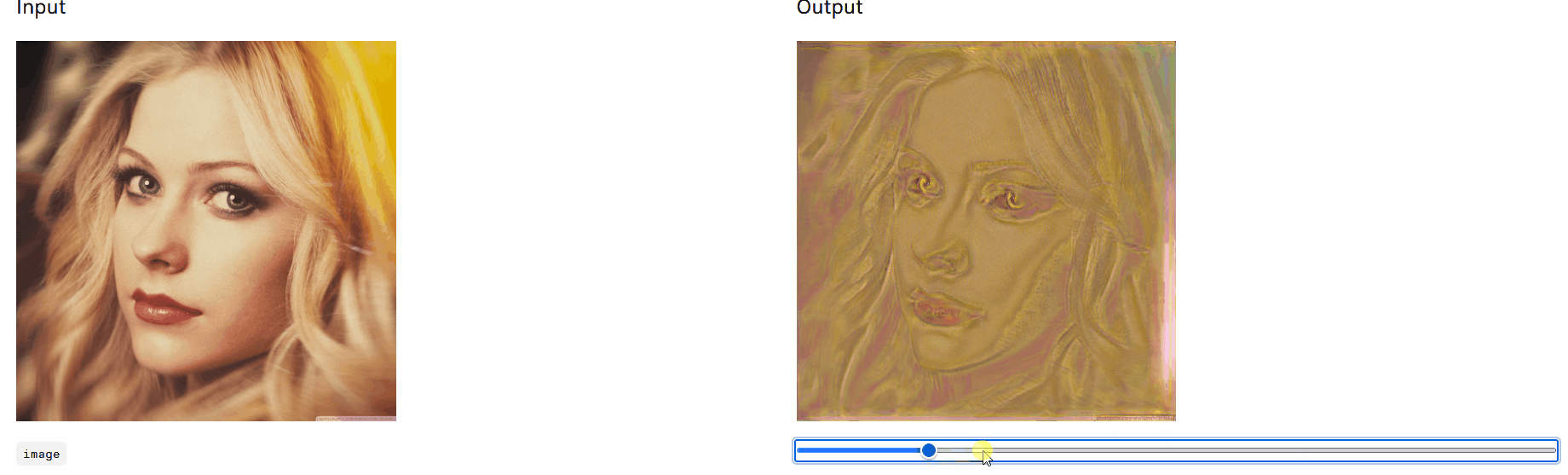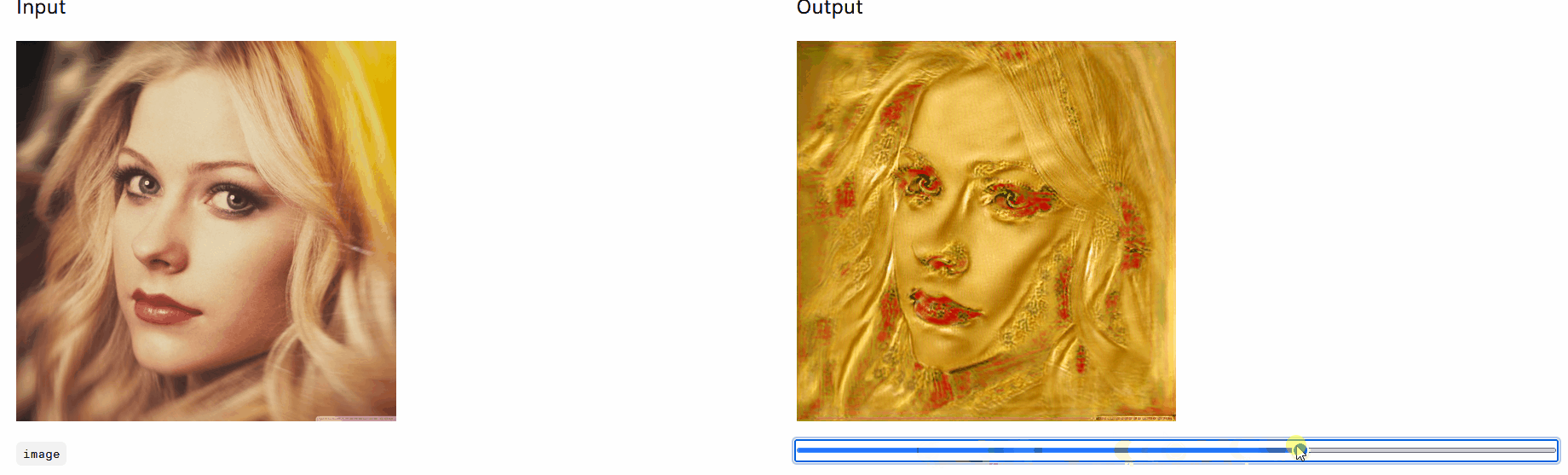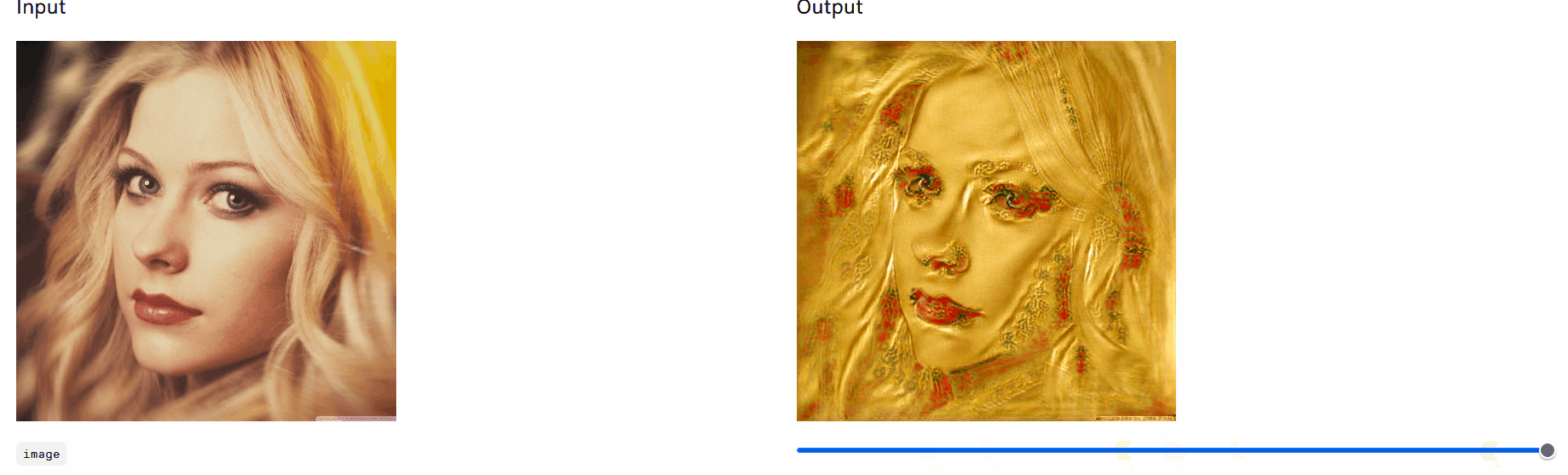
左图原图,文本 “Chinese style” ,训练迭代次数 100 次,右图为输出图像
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
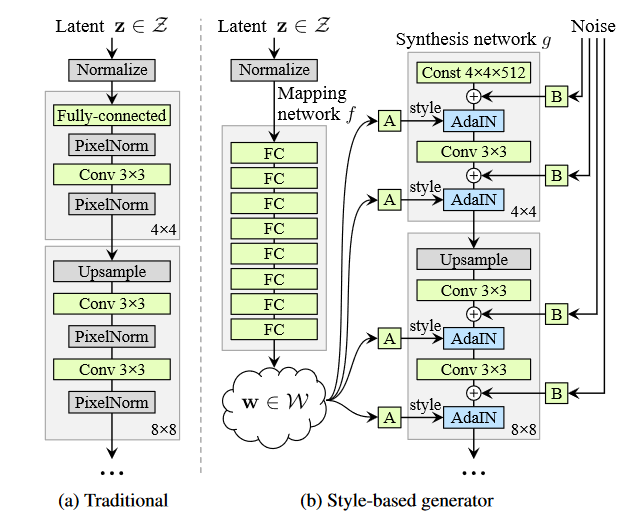
StyleGAN 可以用于生成高质量且真实的图像。然而,想要发掘潜层对于图像的影响对应怎样的语义信息,则需要大量的人工检查以及注释。在这项工作中,作者引入了 CLIP 模型,以帮助 StyleGAN 解除大量人力工作的限制。
StyleGAN 的原理主要是通过 latent code 去控制图像的风格。对于一张图片,先通过 image inversion 将图片表示为latent code,然后去编辑它们,就可以达到编辑图像的目的。
StyleGAN 的网络结构包含两个部分,第一个是 Mapping network,由隐藏变量 z 生成 中间隐藏变量 w的过程,这个 w 就是用来控制生成图像的风格; 第二个是 Synthesis network,它的作用是生成图像。
作者总结了三种将 CLIP 和 StyleGAN 结合的方式:
Latent optimization
这里利用 CLIP 模型计算损失,通过对 latent code 不断迭代,达到图像编辑的目的,需要很多次的迭代,耗时较长。
要解算的是下面这个问题:
Latent Mapper
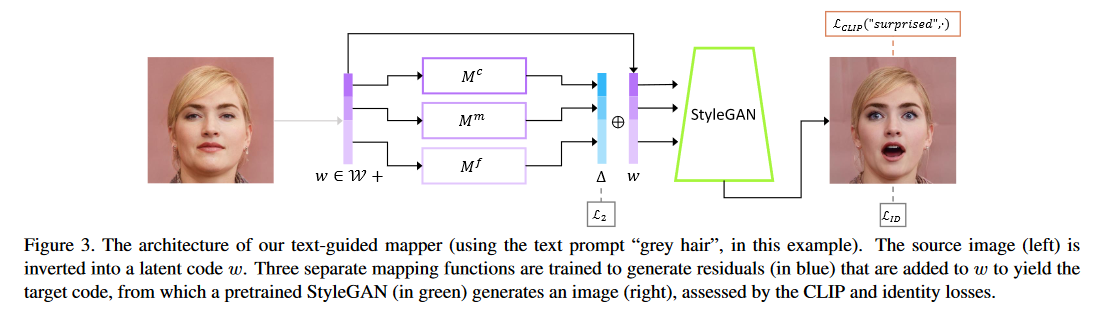
这个方法是指定一些 text prompt 进行训练,模型训练好后只需一次 forward 可以得到结果,通过指定 text prompt,可以预先控制图像编辑的范围区域,这就类似于利用属性分类器来辅助训练,只不过利用CLIP模型可以省略掉分类器,这种方法效率更高。
StyleGAN2 的不同分辨率层控制了不同程度的图像语义,一般分为 coarse, medium, fine 三组。作者通过三个全连接层网络,对 latent code 进行重新编辑,残差连接后进入 StyleGAN 用来生成图像。
Global Directions
这部分比较复杂,还没有搞明白。
实验:利用 CLIP 做简单的图片检索
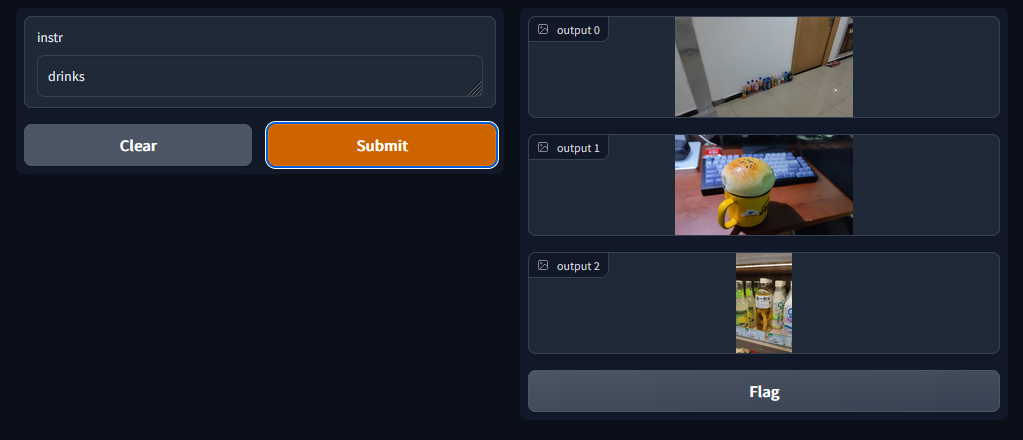
基本流程就是先读入用户的输入,即搜索图片的关键词/句,然后将文本编码得到特征,然后分别对应所有图片的特征计算相似度,取相似度最高的三张图片输出。
图片我没有找网上的一些数据集(因为大部分应该已经有人测试过了),我想看一看这个模型到底有多强大,于是我选取了三十几张我自己拍的一些生活照,进行了一下图像压缩,控制在500kb之内。
展示的部分是利用 Gradio 搭建的,可以迅速将模型转化为交互式的界面。
下面展示几张效果:
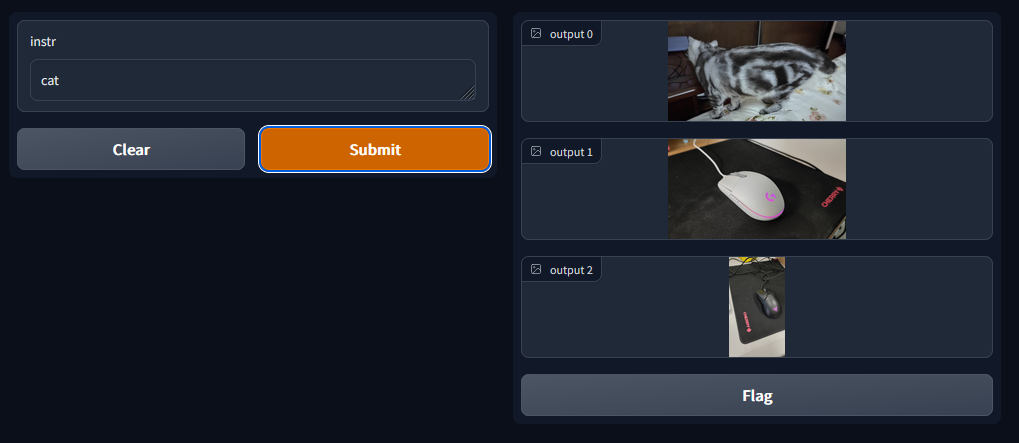
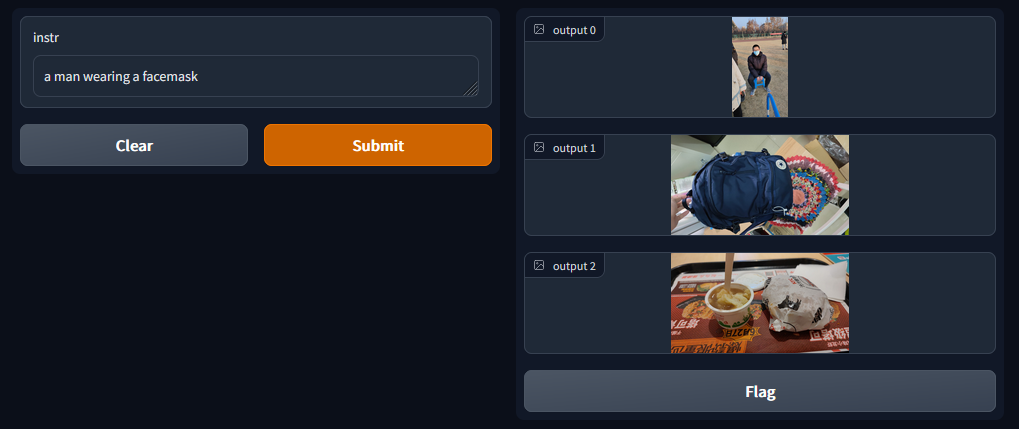
测试的时候发现有意思的地方是这个例子:我这里是输入了这个midi键盘的名称(是刻在键盘上的文字),结果它也能给我识别出来:
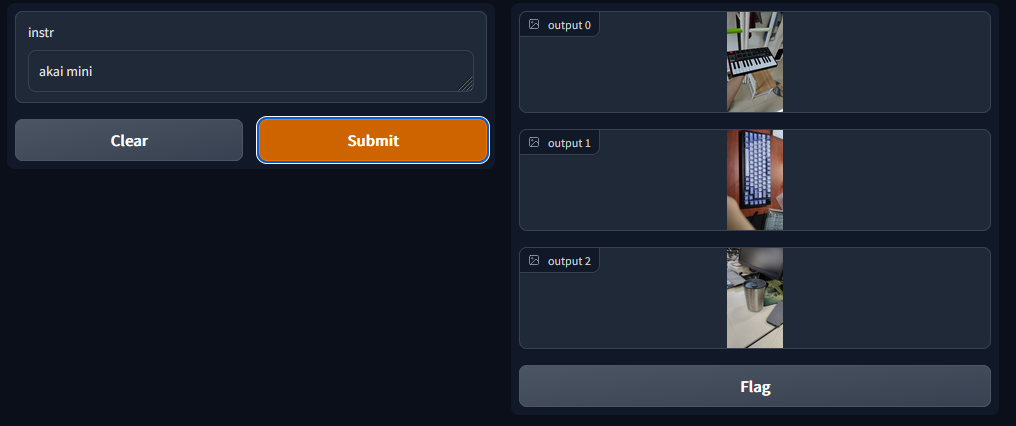

这是否说明 CLIP 模型直接具有 OCR 的能力呢?我的理解是 CLIP 在大量的样本训练中,将每个字母也看做一个对象去学习了他们的特征,所以能够直接识别到图片中的文字了。
代码:(github仓库:https://github.com/1099255210/simple-CLIP-based-image-retrival)
1 | import gradio as gr |
1 | def fn(instr): |
1 | css_output = ".object-contain {height: 100px !important}" |