知识蒸馏 (Knowledge Distillation)
简介
知识蒸馏(Knowledge Distillation, KD)旨在把一个大模型或者多个集成模型学到的知识迁移到另一个轻量级的简单模型上,在模型压缩的思想下实现知识迁移,并方便部署。
虽然在一般情况下,我们不会去区分训练和部署使用的模型,但是训练和部署之间存在着一定的不一致性:
在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
- 推断速度慢
- 对部署资源要求高(内存,显存等)
在部署时,我们对延迟以及计算资源都有着严格的限制。 因此,模型压缩(在保证性能的前提下减少模型的参数量) 成为了一个重要的问题,而”模型蒸馏“属于模型压缩的一种方法。
一个模型的参数量基本决定了其所能捕获到的数据内蕴含的“知识”的量。 这样的想法是基本正确的,但是需要注意的是: 模型的参数量和其所能捕获的“知识“量之间并非稳定的线性关系,而是接近边际收益逐渐减少的一种增长曲线。
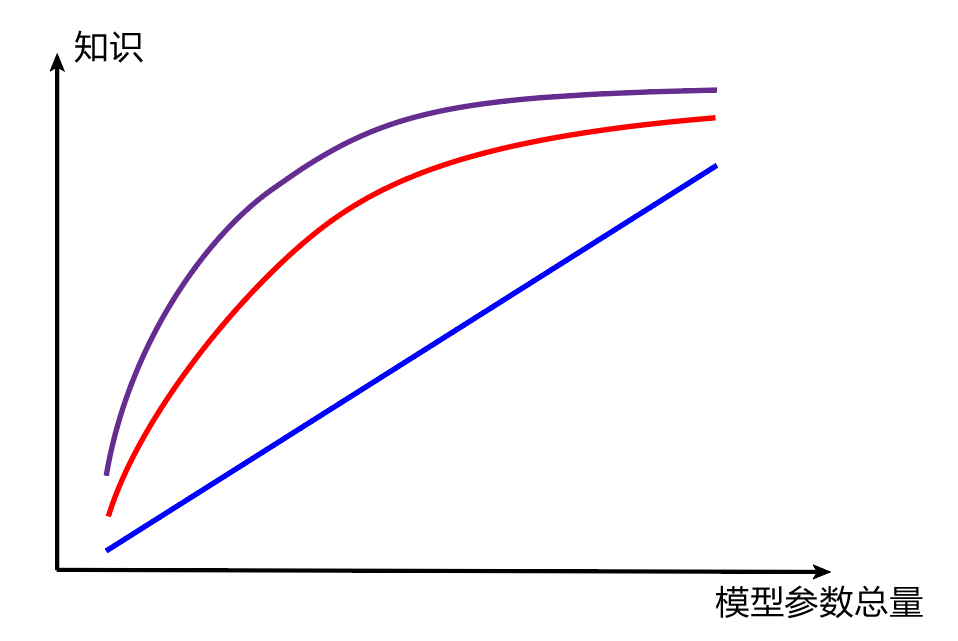
知识蒸馏分为:教师-学生迁移(离线学习)和学生互学习迁移(在线学习)。
知识蒸馏的方法
教师-学生迁移(T-S)
Teacher是“知识”的输出者,Student是“知识”的接受者
分为两个阶段:
- 原始模型训练: 训练”Teacher模型”, 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对”Teacher模型”不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练”Student模型”, 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
关键点:机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。模型 Net-T 本身泛化能力较强,在训练 Net-S 时可以直接让它学习 Net-T 的泛化能力,具体方法就是用 Net-T softmax层输出的各类别的概率作为 soft target,而不是只使用基于 ground truth 的 hard target。
在 softmax 层的输出中除了正例之外,负标签也具有大量的信息,尤其当 soft target 的分布熵相对高时,蕴含的知识就更加丰富。
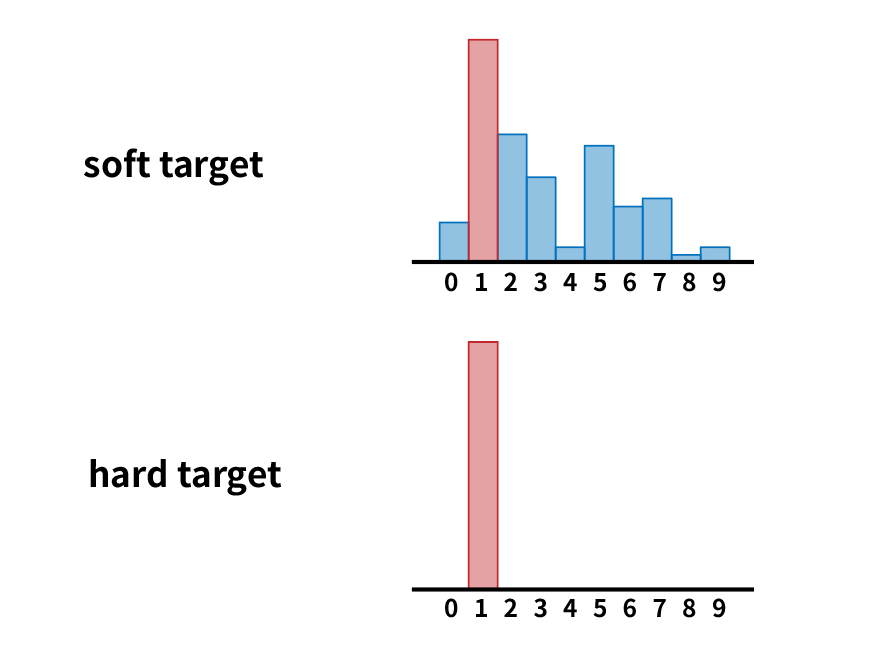
这里如果直接用原始的 softmax 输出作为 soft target,在概率分布熵较小(即负标签值都比较接近于0)的情况下对损失函数的贡献偏小,因此需要引入“温度”这个参数。
原始的 softmax:
引入温度:
$T$的值越大,分布熵越大,负标签携带的信息会相对放大,模型训练将更加关注负标签。
总体的Loss函数由 soft target 和 hard target 加权得到:
需要 hard target 的原因是,Net-T 也有一定的错误率,加入 ground truth 的判别可以有效降低错误被传播给 Net-S 的可能性。
在温度的选取方面,如果 Net-S 的参数量较小,那么选取相对比较低的温度就可以了,因为参数量小的模型可能不能学习到所有的知识,可以适当忽略掉一些负标签的信息。
(这部分的后续内容有待以后扩充)