Transformer 笔记
输入 -> 编码 -> 解码 -> 输出
Transformer 结构
注意点:
每个小 Encoder 结构都是一样的,但是参数都不同,分别训练
每个小 Decoder 结构都是一样的,但是参数都不同,分别训练
Encoder 和 Decoder 是不一样的
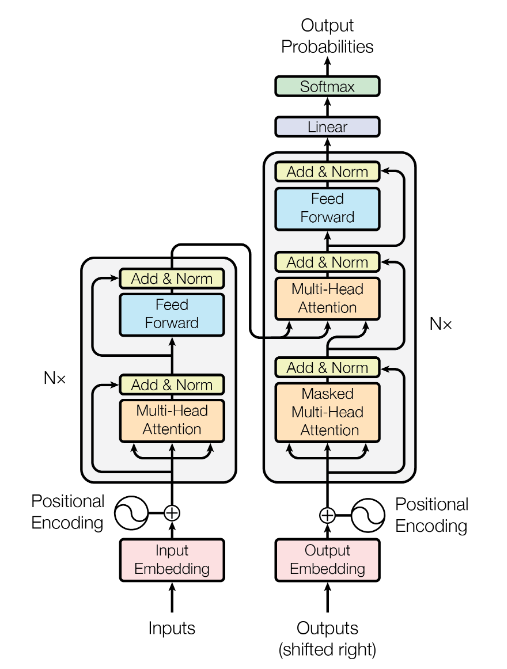
这里的N在文章中为6
Encoder 和 Decoder
Encoder
结构 : 输入、注意力机制、前馈神经网络
六个大的模块之间是串行的
每一个模块注意力层和前馈神经层自身可以并行计算,不同单词之间没有依赖关系;注意力层和前馈神经层又是串行关系。
输入
包括:
Embedding
位置编码
位置编码记录了词序信息。
关于位置编码,对于所有的 timeline 上的位置共享一套参数
RNN 网络输入有天然的时序关系;Transformer 的 multihead 机制是同时处理所有输入的,忽略了时序关系,因此需要位置编码。
位置编码的公式:
$PE_{(pos,2i)}=\sin(pos/10000^{2i/d_{model}})$
$PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d_{model}})$
其中 $i$ 是位置编码维度(如 0-511)
位置编码(512d)+Embedding(512d)得到 transformer 的输入
位置嵌入有效的原因:在绝对位置信息中包含相对位置信息,$pos+k$ 位置的位置向量中的某一维 $2i$ 或 $2i+1$ 能够被 $pos$ 位置和 $k$ 位置的位置向量中的 $2i$ 和 $2i+1$ 维线性组合。但这种相对位置信息会在注意力机制那里消失。
推理公式:
$PE_{(pos+k,2i)}=PE_{(pos,2i)}\times PE_{(k,2i+1)}+PE_{(pos,2i+1)}\times PE_{(k,2i)}$
$PE_{(pos+k,2i+1)}=PE_{(pos,2i+1)}\times PE_{(k,2i+1)}-PE_{(pos,2i)}\times PE_{(k,2i)}$
注意力机制
$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
$Q$ 是输入,点乘 $K$(表示区域),得到相似度向量,softmax 归一化后乘 $V$ 得到 Attention Value
在只有单词向量的情况下,将单词向量与 $QKV$ 矩阵相乘得到 $QKV$ 向量。
作归一化的原因:随着$d_k$的增大,$QK^T$的结果也随之增大,而如果点乘后的值过大,会导致softmax函数趋近于边缘,梯度较小。为了抵消影响,需要将点积缩放。
Normalization
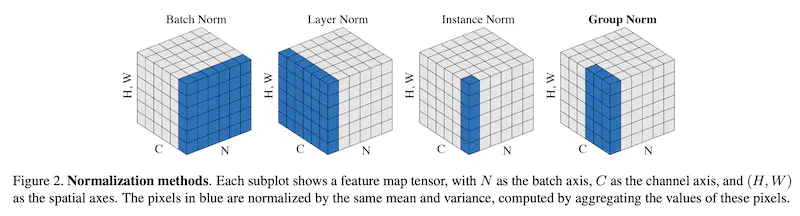
CV 使用 Batch Norm
BN 是对于每一个特征在 batch_size 上作特征缩放。
BN的:
- 优点:可以解决内部协变量偏移;缓解了梯度饱和问题,加快收敛
- 缺点:batch_size 较小的时候效果差;在 RNN 中效果比较差,因为输入是动态的,不能有效地得到整个batch_size 中的均值和方差。
NLP 使用 Layer Norm
LN是针对每一个样本进行特征缩放。
为什么 CV 任务用 BN 而 NLP 任务使用 LN ?
词向量是学习出来的用来表示语义的参数,不是真实存在的;而图像的像素是真实存在,包含图像特征的信息。