目的
对于 DUC2004 数据集的 50 个 topic 生成文本摘要,并将生成的摘要与 baseline,共同和专家组的摘要做 Rouge 评分。
数据集地址:(https://www-nlpir.nist.gov/projects/duc/data/2004_data.html)
预处理数据
预处理数据分为以下几步:
句子切分
句子切分一开始我使用的是用 . 即英文的句号进行分割,但是后来在检查结果的时候发现有些单词比如 U. N. 会被误认为是多个句子。于是我借用了 nltk 库的 tokenize 函数进行句子的分割,有效避免了这个问题,当然也同时避免了无法区分以非英文句号为结尾的句子的情况。
1 | tokenizer = nltk.data.load('tokenizers/punkt/english.pickle') |
去除停用词
句子切分完之后,就可以以空格为分割符提取句子中的每个单词。提取的时候要注意的地方是:单词前后可能有特殊符号需要去除;单词可以直接统一转为小写;单词中的数字也要去除。这里用正则表达式对单词处理。
1 | word = re.sub("[^A-Za-z]+", ' ', str(word)).lower().strip() |
得到每一个单词之后,需要去除停用词,比如 a, the 等等。
停用词去除的工作也是调用 nltk 库中的 stopwords ,只要检查单词是否在停用词中然后省略即可。
1 | from nltk.corpus import stopwords |
单词词干化(https://tartarus.org/martin/PorterStemmer/)
这一步课件里给出了一个停用词去除的库 PorterStemmer 网站上直接可以下载到源码。保存至 porterstemming.py 之后实例化一个 PorterStemmer 对象,之后进行单词词干化。
1 | import porterstemming |
对每一个句子进行如上操作之后,将句子与句子中经过处理的单词序列存入一个数据结构中待使用;每篇文章里的所有句子也存入一个数据结构中,用于下一步分析单词与句子的统计特性。
DUC 文本数据转化为数值型数据
这里课件里引入 TF-IDF 的概念:
$词频(TF) = \frac{某个词在文章中的出现次数}{文章的总词数}$
$逆文档频率(IDF)=log(\frac{语料库的文档总数}{包含该词的文档数+1})$
$TF-IDF=词频(TF)×逆文档频率(IDF)$
但是要用这样的概念生成 句子-词语 矩阵,似乎不可行,因为这其中没有句子的概念。这里可以采用另一个概念 TF-ISF 来生成矩阵:
$词频(TF) = \frac{某个词在句子中的出现次数}{句子的总词数}$
$逆文档频率(ISF)=log(\frac{语料库的句子总数}{包含该词的句子数+1})$
$TF-ISF=词频(TF)×逆文档频率(ISF)$
通过这样的公式,对每一个 topic 中的句子与单词分别计算 句子-词语 矩阵。
为了方便后期的处理,在矩阵的最后一列加入一行 同一个主题里所有句子拼接起来的一个长句子。
计算相似度
生成的矩阵现在可以用于计算句子与句子间的相似度。我们将所有的句子与最后的长句子(所有句子拼接而成的句子)进行余弦相似度的计算,公式如下:
$\cos\theta=\frac{\sum_{i=1}^n(A_i×B_i)}{\sqrt{\sum_{i=1}^n(A_i)^2}×{\sqrt{\sum_{i=1}^n(B_i)^2}}} \\ = \frac{A\cdot{B}}{\mid{A}\mid×\mid{B}\mid}$
定义函数 calSimilarity(arr1:numpy.ndarray, arr2:numpy.ndarray) 输入两个向量计算相似度。
1 | # Similarity Calculation |
得到每个句子对最后的长句子的相似度之后进行排序。
1 | simvaluedict = sorted(simvaluedict.items(), key=lambda item: item[1], reverse=True) |
最终得到一个按照相似度数值高低排序的矩阵,每行代表一个句子以及其相似度值。
冗余控制与摘要生成
上一步得到的矩阵中,我们选取相似度值最高的句子放入最终的摘要中,然后选取第二句,与第一句作相似度计算,如果高于某个阈值,则丢弃,直到文本的大小达到 665byte 为止。这里的阈值我经过试验之后设为了 0.4,实验中如果阈值过高很可能导致摘要长度还未达到规定大小就生成结束,最终导致摘要过短。
至此,每个 topic 的摘要内容生成完毕。
摘要性能评测
对于生成的摘要,我将其与数据集中专家给出的几份摘要都作 ROUGE 的计算,得到的最高分计入最终结果。这里的 ROUGE 评分主要有三项:ROUGE-1, ROUGE-2, ROUGE-l,着重关注的是回归率 r。
为了作对比,还需要提供一个 Baseline 结果,这里对于每一个 topic 里的每一篇文章选取第一句话拼接为一个摘要,长度同样为 665byte,再对比专家组结果作 ROUGE 评分。
将两者进行对比,绘制直方图:
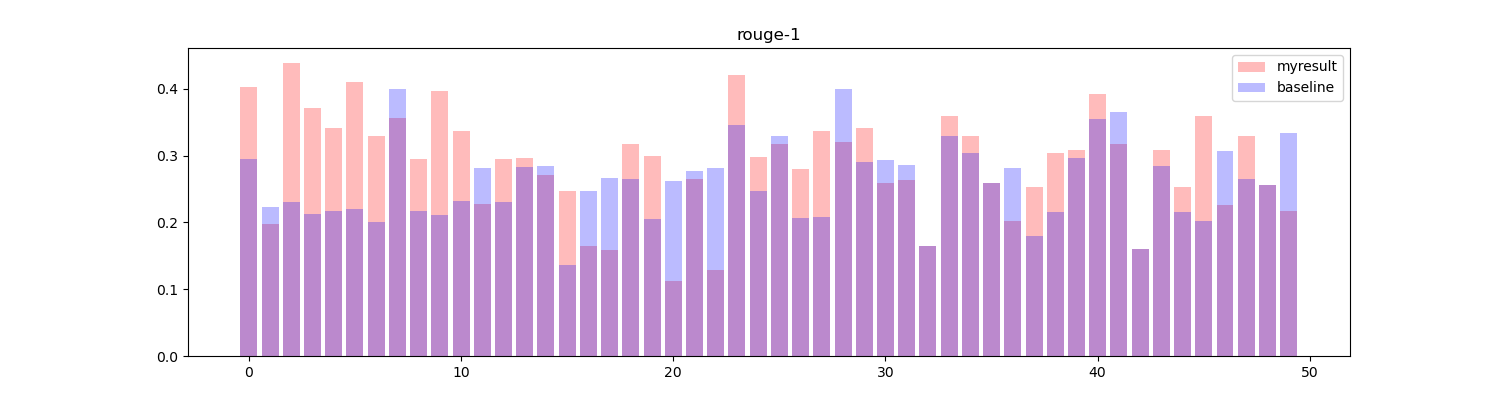
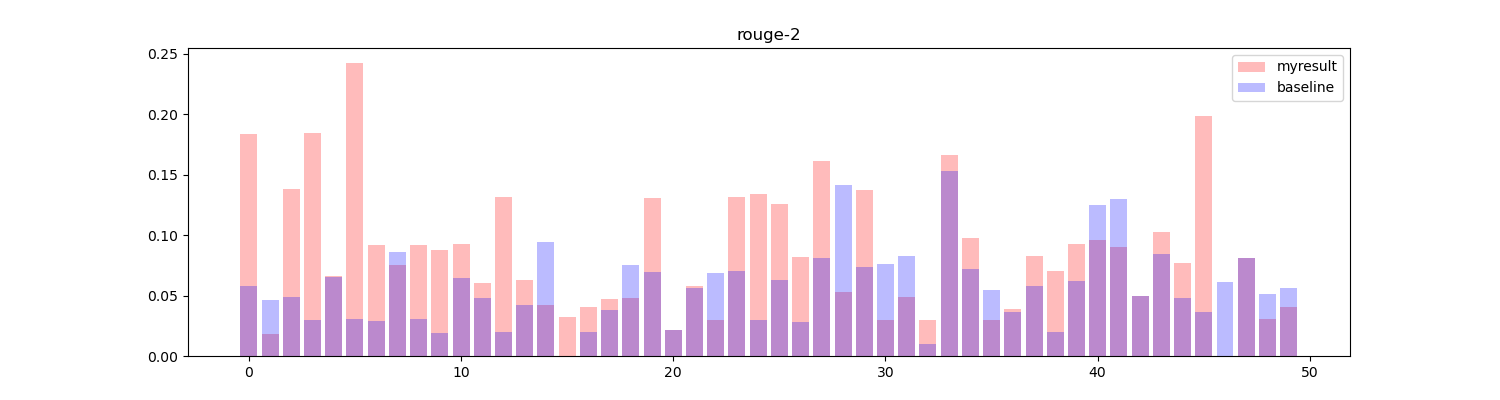
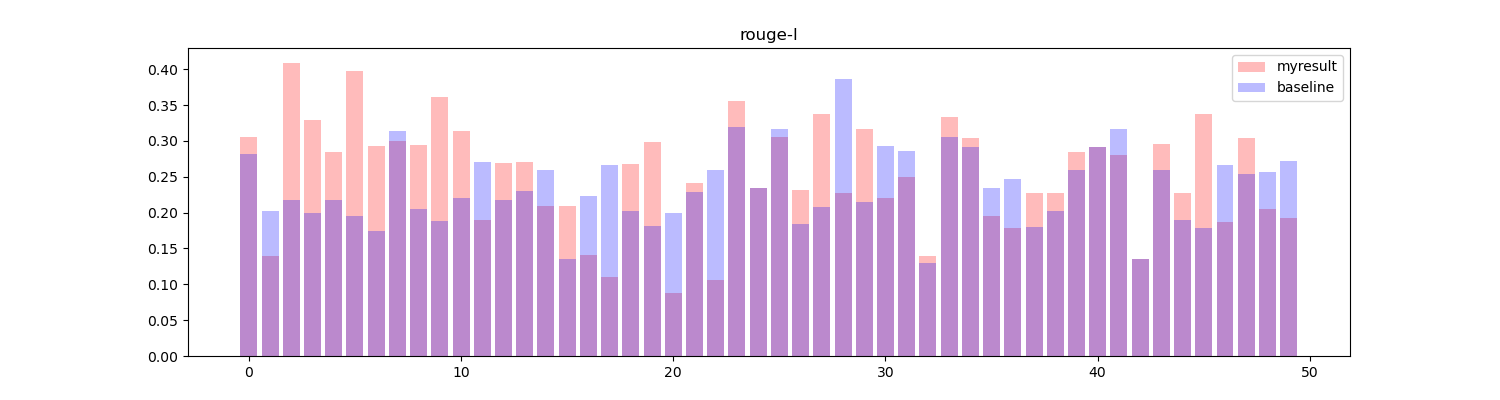
红色部分为算法生成的结果,蓝色部分为基线结果,可以看到在大部分 topic 中得到的效果要高于或等于基线效果(33/50)。
关于算法的改进
改进方法中我选择了改进方法2进行实验。
调查了一下 sentence2vec 的方法,发现首先需要有个词向量的数据 (word2vec)。网络上找到的方法是使用 gensim 库对语料库进行训练,得到 word2vec 的数据之后再计算句向量,剩下的内容就和之前差不多了,也是计算相似度之后排序生成摘要。
我尝试用原始的文档训练词向量,然后计算句向量,但是得到的结果有很大的问题。问题主要在于使用原始文档训练出来的词向量计算出的句向量,这些向量之间的相似度极高,基本都高达 99% 以上,对这样的相似度数据进行排序显然没有任何意义。
于是我找到了一个预训练的数据集 GloVe: Global Vectors for Word Representation,选取了其中一个 50 维的词向量数据集作为参考。这里就注意不需要对每个词进行词干化了,否则在词向量数据中是找不到对应向量的,默认会置0,也就是没有意义的。
sentence2vec 句向量的计算参照以下公式:
$v_s\leftarrow{\frac{1}{\mid s \mid}}\sum_{w\in s}{\frac{a}{a+p(w)}v_w}$
算出句向量之后就可以像之前一样进行相似度计算排序然后生成了。
但是令人意外的是这样生成的摘要得到的效果反而不如之前的算法生成的效果,结果如下:
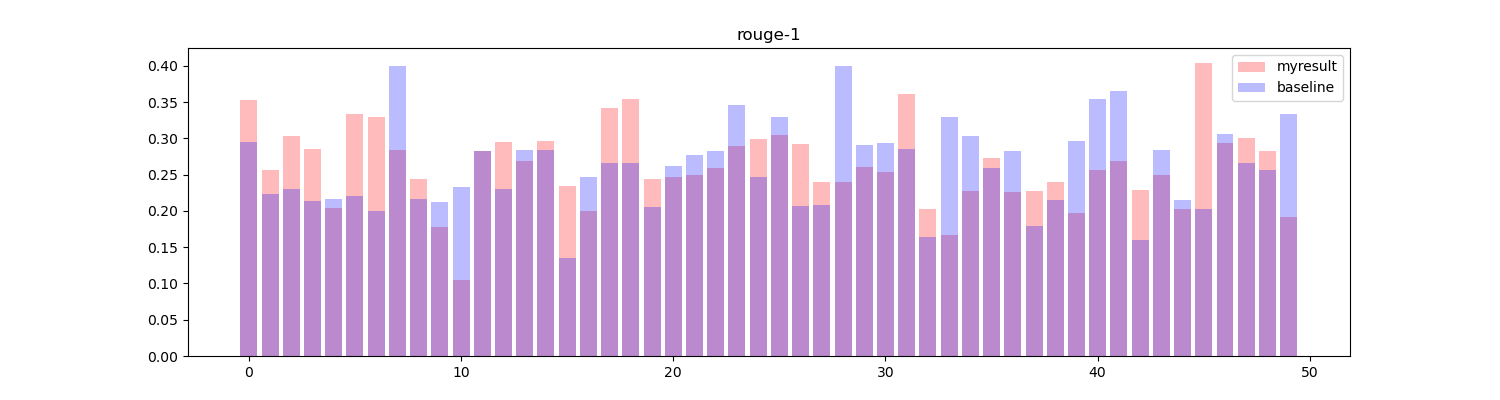
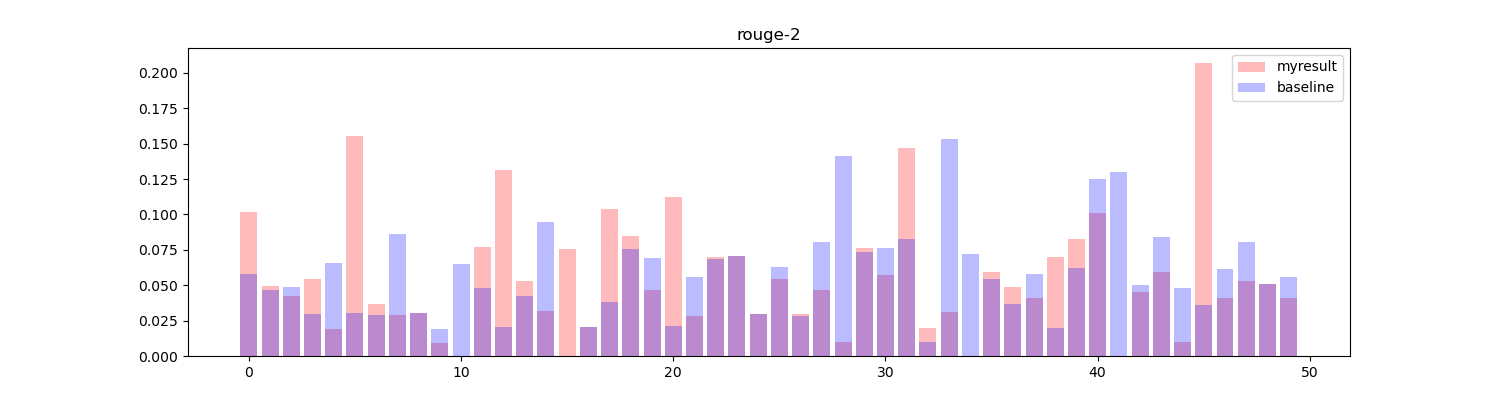
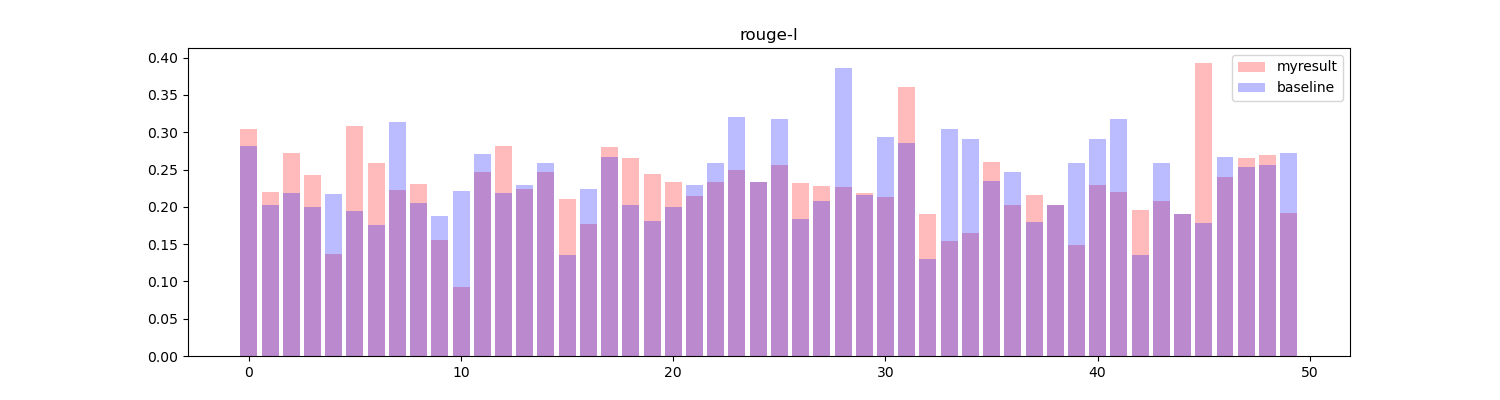
但是结果确实是如此,我检查代码也没有发现有什么明显的问题。可能这个词向量的数据集对于该任务来说并不适合吧。